什么是机器学习
机器学习是指:使计算机针对某个特定的任务,从经验中学习,并且越做越好。而经验,就是数据;学习,就是利用经验训练模型的过程。
机器学习的分类
根据数据可以分为两类:
- 数据有标记——有监督学习;
- 数据无标记——无监督学习。
标记是指数据是否将已知的输入与输出相匹配,比如已经将邮件(输入)标记为垃圾邮件(输出)。
Python机器学习环境
- Python
- IPython(即Jupyter Notebook)
- Numpy
- Scipy
- Pandas
- Matplotlib
- scikit-learn
IPython常用命令
%run [hello.py]hello.py 是当前工作目录下的一个文件,该命令在一个空命名空间里运行该文件,并将文件里定义的全局变量和函数就会自动引用到当前 IPython空间中。%timeit [代码]评估代码运行的效率(时间)%who%whos查看当前环境的变量列表%matplotlib inline使 matplotlib 的的图片直接画在网页上
Numpy常用方法
在此不详述。
Pandas简介
在此不赘述。
Matplotlib简介
在此不废口舌。
scikit-learn简介
scikit-learn是一个开源机器学习库。
机器学习的步骤
下面以手写数字识别为例,简述机器学习的步骤,具体原理将在后面介绍
数据的采集和标记
先采集数据,即让尽量多不同书写习惯的用户,写出从 0 ~ 9的所有数字,然后把用户写出来的数据进行标记,即用户每写出一个数字,就标记他写出的是哪个数字。
所幸我们不需要从头开始这项工作, scikit-learn自带了一些数据集,其中一个是手写数字识别图片的数据,使用以下代码来加载数据。
from sklearn import datasets
digits = datasets.load_digits()
print(digits)
可以通过matplotlib将图片输出:
%matplotlib inline
from matplotlib import pyplot as plt
images_and_labels = list(zip(digits.images, digits.target))
plt.figure(figsize=(8, 6), dpi=100)
for index, (image, label) in enumerate(images_and_labels[:8]):
plt.subplot(2, 4, index + 1)
plt.axis('off')
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.title('Digit: %i' % label, fontsize=20)
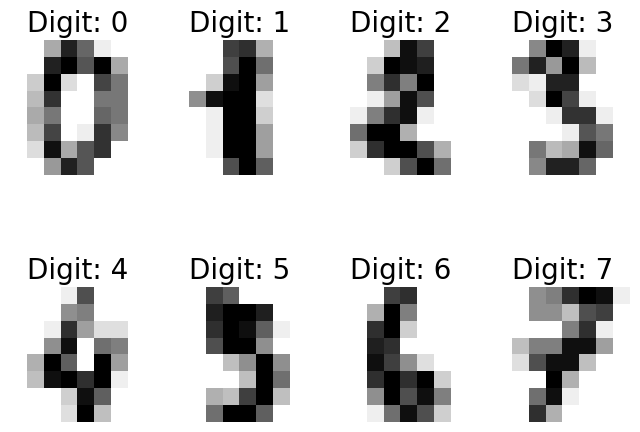
特征选择
数据有很多特征,我们需要选择输入到模型中的特征。针对一个手写的图片数据,应该怎么样来选择特征呢?一个直观的方法是,直接使用图片的每个像素点作为一个特征。
实际上,scikit-learn 使用 Numpy 的 array 对象来表示数据,所有的图片数据保存在 digits.images 里,每个元素都是一个 8*8尺寸的灰阶图片。我们在进行机器学习时,需要把数据保存为样本个数*特征个数格式的 array对象,针对手写数字识别这个案例, scikit-learn已经为我们转换好了,它就保存在 digits.data数据里,可以通过 digits.data.shape来查看它的数据格式为:
print(" shape of raw image data: {0}".format(digits.images.shape))
print(" shape of data: {0}".format(digits.data.shape))
shape of raw image data: (1797, 8, 8)
shape of data: (1797, 64)
数据清洗
数据清洗,即把采集到的、不适合用来做机器学习训练的数据进行预处理,从而转换为适合机器学习的数据。
在这个例子中,就是把手写的大图缩小为8*8的小图
模型选择
不同的机器学习算法模型针对特定的机器学习应用有不同的效率,模型的选择和验证留到后面章节详细介绍。此处,我们使用支持向量机来作为手写识别算法的模型。关于支持向量机,后面也会详细介绍。
模型训练
在开始训练我们的模型之前,需要先把数据集分成训练数据集和测试数据集。使用下面代码把数据集分出20%作为测试数据集。
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(digits.data,
digits.target,
test_size=0.8,
random_state=2)
接着,使用训练数据集 Xtrain和 Ytrain来训练模型。
# 使用支持向量机来训练模型
from sklearn import svm
clf = svm.SVC(gamma=0.001, C=100.)
clf.fit(Xtrain, Ytrain)
SVC(C=100.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
clf.score(Xtrain, Ytrain)
1.0
模型测试
用训练出来的模型 clf预测测试数据集,然后把预测结果 Ypred和真正的结果 Ytest比较,看有多少个是正确的,这样就能评估出模型的准确度了。所幸, scikit-learn提供了现成的方法来完成这项工作:
clf.score(Xtest, Ytest)
0.9791376912378303
也就是说,模型有97.8%的准确率。此外,可以直接把测试数据集的图片显示出来,并且在图片的左下角显示预测值,右下角显示真实值。
#查看预测的情况
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
fig.subplots_adjust(hspace=0.1, wspace=0.1)
Ypred = clf.predict(Xtest)
for i, ax in enumerate(axes.flat):
ax.imshow(Xtest[i].reshape(8, 8),
cmap=plt.cm.gray_r,
interpolation='nearest')
ax.text(0.05,
0.05,
str(Ypred[i]),
fontsize=32,
transform=ax.transAxes,
color='green' if Ypred[i] == Ytest[i] else 'red')
ax.text(0.8,
0.05,
str(Ytest[i]),
fontsize=32,
transform=ax.transAxes,
color='black')
ax.set_xticks([])
ax.set_yticks([])

模型保存与加载
当我们对模型的准确度感到满意后,就可以把模型保存下来。这样下次需要预测时,可以直接加载模型来进行预测,而不是重新训练一遍模型。
#保存模型参数
import joblib
joblib.dump(clf, 'digits_svm.pkl')
['digits_svm.pkl']
#导入模型参数,直接进行预测
clf = joblib.load('digits_svm.pkl')
Ypred = clf.predict(Xtest)
clf.score(Xtest, Ytest)
0.9791376912378303
scikit-learn一般性原理
评估模型对象
scikit-learn里的所有算法都以一个评估模型对象来对外提供接口。上面例子里的 svm.SVC()函数返回的就是一个支持向量机评估模型对象。创建评估模型对象时,可以指定不同的参数,这个称为评估对象参数,评估对象参数直接影响评估模型训练时的效率以及准确性。
需要特别说明的是,我们学习机器学习算法的原理,其中一项非常重要的任务就是了解不同的机器学习算法有哪些可调参数,这些参数代表什么意思,对机器学习算法的性能以及准确性有没有什么影响。因为在工程应用上,要从头实现一个机器学习算法的可能性很低,除非是数值计算科学家。更多的情况下,是分析采集到的数据,根据数据特征选择合适的算法,并且调整算法的参数,从而实现算法效率和准确度之间的平衡。
模型接口
scikit-learn所有的评估模型对象都有 fit() 这个接口,这是用来训练模型的接口。针对有监督的机器学习(如上面的例子),使用 fit(x, y) 来进行训练,其中 y是标记数据。针对无监督的机器学习算法,使用 fit(x) 来进行训练,因为无监督机器学习算法的数据集是没有标记的,不需要传入 y。
针对所有的有监督机器学习算法, scikit-learn的模型对象提供了 predict() 接口,经过训练的模型,可以用这个接口来进行预测。
针对分类问题,有些模型还提供了 predict_proba() 的接口,用来输出一个待预测的数据,属于各种类型的可能性,而 predict() 接口直接返回了可能性最高的那个类别。
几乎所有的模型都提供了 scroe() 接口来评价一个模型的好坏,得分越高越好,这个称为准确度。但有些模型需要用查准率和召回率来衡量。相关概念我们后面会详细介绍。
针对无监督的机器学习算法, scikit-learn的模型对象也提供了 predict() 接口,它是用来对数据进行聚类分析,即把新数据归入某个聚类里。除此之外,无监督学习算法还有 transform() 接口,这个接口用来进行转换。
模型接口也是 scikit-learn工具包的最大优势之一,即把不同的算法抽象出来,对外提供一致的接口调用。
模型检验
检测我们训练出来的模型,针对“没见过的”陌生数据其预测准确性如何。
模型选择
模型选择是个非常重要的课题,根据要处理的问题性质,数据是否经过标记?数据规模多大?等等这些问题,可以对模型有个初步的选择。 scikit-learn的官方网站上提供了一个模型速查表,只要回答几个简单的问题就可以选择一个相对合适的模型。可以搜索 scikit-learn algorithm cheat sheet来查看这个图片.

