网络层概论
数据链路层关注的是线路两端的传输;而网络层关注的是源机到目的机的传输,由于中间会经过 ISP(网络服务提供商)的路由网络,因此网络层的工作就是找到一条合适的路由路径。这个路径可能是固定的,称为 面向连接的服务;也可能是变化的,称为 无连接的服务。
无连接的服务
无连接的服务中,每个数据包独立路由,不需要提前建立路径。这种数据包称为 数据报,就像电报,对应的网络称为 数据报网络。
数据报网络的工作过程如下:数据报中会携带目的机的地址。每个路由器都维护着一张路由表,表有两列:目标地址和对应的出境线路,根据路由表来转发数据报。
比如在下图中,H1 发送一个数据报到 H2,路由器 A 收到数据报后,在路由表中查找去路由器 F 的出口,查到是 C,于是发送到 C,然后 C 再查路由表……最终经过 A-C-E-F 的路径到达 H2.
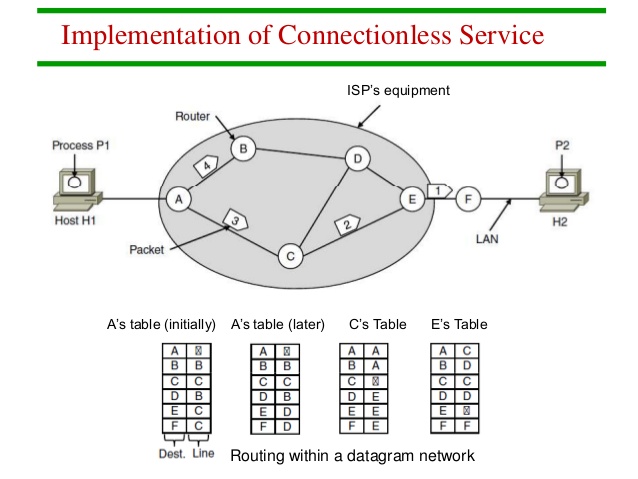
如果某条路径上发生了流量拥塞,假设是 A-C,那么路由器就会自动更新路由表,A 的路由表就变为图中 later 那样。建立、维护路由表的协议叫 路由选择协议,管理路由表的算法叫做 路由算法(route algorithm)
面向连接的服务
面向连接的服务中,发送数据包前要建立一条路径,称为 虚电路(VC,Virtual circuit),就像电话系统中那样,对应的网络称为 虚电路网络。
虚电路网络的工作过程如下:发送数据包前先建立一条虚电路,存储在每个路由器的路由表中,用标识符1区分。每个数据包同样有一个标识符,指明它用哪条虚电路。等所有数据包发完后,释放连接。
比如在下图中,建立虚电路后,H1 发送数据报到 H2,路由器 A 从 H1 接受到一个标识符为 1 的数据包,于是将它发送到 B,并赋予标识符 1,然后 B 再重复该过程……最终经过 A-C-E-F 传给 H2. 以后再发包也是用相同的路径。
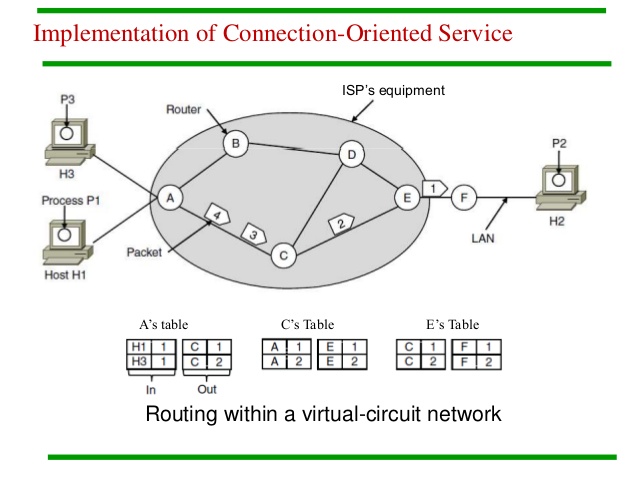
值得注意的是,路由器在转发时会给数据包赋予新的标识符,称为 标签交换。这是因为,对源端来说,标识符指的是源端的第几条虚电路,并不是全局的编号。同样,对路由器来说,标识符指的是某个端口上的第几条虚电路,也不是全局的。Anyway,千万不要认为某条路径上的所有标识符都是一致的。
| 问题 | 数据报网络 | 虚电路网络 |
|---|---|---|
| 电路建立 | 不需要 | 需要 |
| 寻址 | 包含源和目标地址 | VC号(标识号) |
| 路由方式 | 数据报单独路由 | 建立VC时选择路由,所有包都用该路由 |
| 状态信息 | 不保留 | 保留每个连接的状态 |
| 路由器失效 | 无影响 | 有影响 |
| 服务质量/拥塞控制 | 困难 | 简单 |
IP
Internet 由多个骨干网以及连接到骨干网上的 ISP(网络服务提供商)构成。而 Internet Protocal(IP协议)则用于将这些网络黏合在一起。
Internet 的通信过程:
- 传输层获取数据流,并分段,作为 IP 数据包发送(数据包最多容纳 64KB,为了兼容以太帧,通常不超过 1500 Byte)
- IP 路由器转发数据包,穿过 Internet,到达目标机器
- 目标机器的网络层还原成最初的数据报,并传给传输层
IP 协议
IP 数据报的格式分为:头+正文(也叫有效净荷)。头的格式为:20byte定长部分+变长部分,如下(从左到右,从上到下传输):

各个字段的意义如下:
- 版本:协议的版本,目前常用的是 4,也就是 IPv4
- IHL:头部长度
- 服务类型:
- (修改前)前 3 位是优先级,后 4 位表示延迟、吞吐量、可靠性、花费哪个最重要,最后 1 位置0。然而,没人只要要怎么用。
- (修改后)前 6 位表示服务类型,后 2 位表示拥塞通知信息。
- 总长度
- 标识:确定分段属于哪个数据报
- DF:Don’t Fragment
- MF:More Fragment 除最后一段,其他段都置1,用于判断所有段是否都到达。
- 分段偏移量:该段在数据报中的位置
- 生存期:一开始设置为 255,每一跳减 1,避免数据包永远逗留在网络中
- 协议:传输层采用的协议
- 校验位:将其他字段按 16 位累加取补码,这样接收方将所有字段按 16 位累加的结果为 0.(每一跳都会重新计算)
- 源地址:后面介绍
- 目标地址:后面介绍
- 选项(不介绍)
P.S. 这里有个 Big-endian 的问题需要注意,详情去看:CSDN:大端、小端、与网络字节序 和 Tcp/IP 协议
IP 地址
IP 地址用来区分源地址和目标地址。一个 IP 地址指向的是一个网络接口,而不是一台主机。路由器有多个接口,所以有多个 IP 地址。
IP 地址有 32bit,一般分成 4 个 8bit,用 4 个十进制数表示,用 . 隔开。比如:
130.1.1.1
192.168.1.1
211.66.11.192/24
那么 IP 是不是随意分配的呢?显然不是(不然每个路由器的路由表就多到爆炸了)。实际上 IP 的分配有点像树:
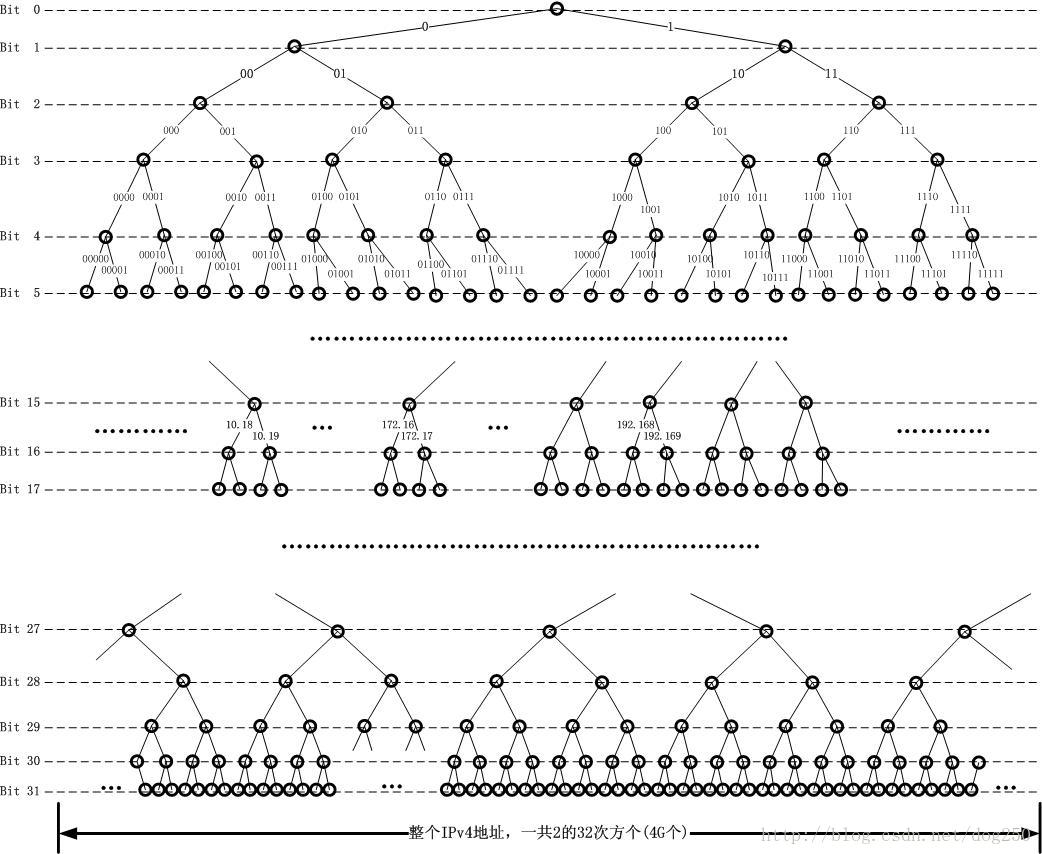
从图中可以看出,每棵子树的前几个bit都是一致的,并且第一个bit对应第一层,第二个bit对应第二层。所以说:IP 地址有层次性。
每个 IP 地址由高位的 可变长网络部分(前缀)2 和 主机部分 组成。同一网络下的主机有相同的前缀,因此一般用前缀来代表某个子网。为了表明前缀的长度,我们一般在 IP 地址后面加条 /,然后写上前缀的位数(比如上面最后一行的例子)。在路由算法中,会以十进制掩码的形式将前缀长度告知路由器,称为 子网掩码,比如:
IP地址:211.66.11.192/24
子网掩码:255.255.255.0
IP地址 && 子网掩码 = 211.66.11.0 ➡ 前缀
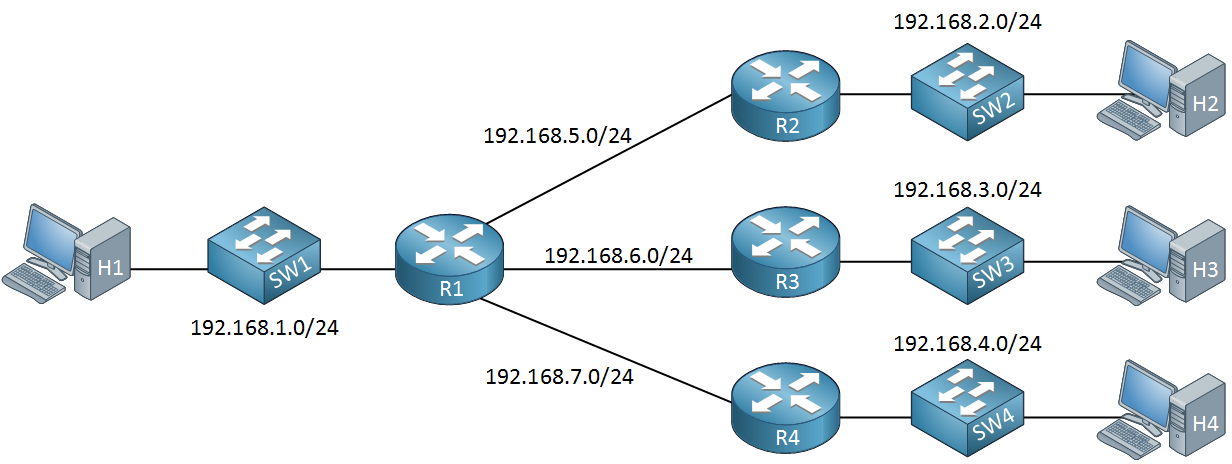
利用 IP 地址的层次性,我们可以将一块网络内部分为多个 子网,但对外仍然像单个网络,称为 子网划分。比如在下面这个例子中,尽管内部有3个子网,但外部用 192.168.1.0 来代表整块网络。(这也是为什么路由器需要知道子网掩码的原因)
IP 分层的优缺点:
- 优点
- 路由器根据网络部分即可转发数据包(同一网络上的主机在同一方向)
- 路由表只需要收录子网即可,可以减小路由表的大小
- 缺点:
- 每个 IP 只属于特点的网络,而 MAC 则可以用于任何地方
- 层次结构浪费了空间(一个前缀下的空间不能用于另一个前缀)
IP地址一开始是采用 分类寻址3 的分配方式,后来发现这个分得不够细、不够好,就改成了现在用的 CIDR。
ICANN 负责全球 IP 地址和域名的分配。ICANN 一次把部分地址空间授权给各个区域,这些机构再把 IP 地址发给 ISP,ISP 再给用户。咱国家最大的IP分配机构叫 CNNIC。
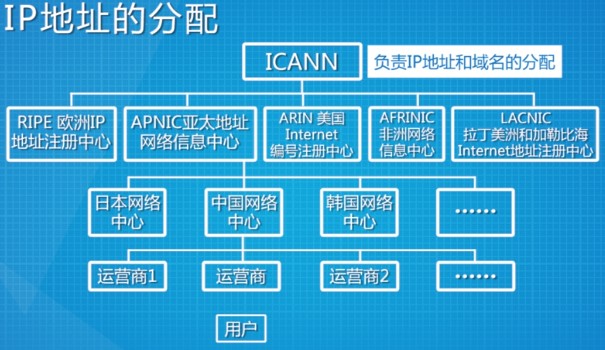
分类寻址
IP 地址根据前缀划分为 A、B、C、D、E 五类:
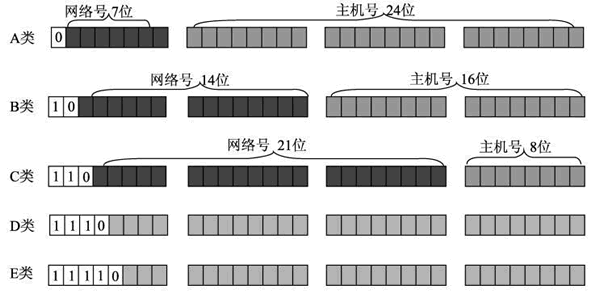
A、B、C 对应 大、中、小规模网络;D 类用于组播;E 类用于科研。
在进行 IP 地址分配时,有一些 IP 地址具有特殊含义,不会分配给互联网的主机。例如,保留了一些 IP 地址范围,用于私有网络,这些地址被称为私有地址。再如,保留一部分地址用于测试,被称为保留地址,比如(记私有地址):
- A类地址
- 私有地址范围为 10.0.0.0~10.255.255.255。
- 保留地址范围为 127.0.0.0~127.255.255.255。
- B类地址
- 私有地址范围为 172.16.0.0~172.31.255.255。
- 保留地址为 169.254.X.X。
- C类地址
- 私有地址范围为 192.168.0.0~192.168.255.255。
另外,还有几个特殊的 IP 地址(要记!):
- 网络地址:主机部分全部为 0
- 广播地址:主机部分全部为 1
- 0.0.0.0:表示主机或网络本身,是路由表中默认路由的目的地址
- 255.255.255.255:泛洪广播地址,指互联网上的所有机器,但为了防止广播风暴,已经退化成的本地广播地址。
- 127.0.0.0:环回地址,127.0.0.1 指本机
- 169.254.0.0:非正常地址,这个地址用于当DHCP服务器故障,或者DHCP超时,不致于设备没有IP而造成连接不上。
127.0.0.1 与 0.0.0.0 的区别:
127.0.0.1 是回环地址,发向这个地址的数据包都发回给自己。
0.0.0.0 是未知/不可用目标的地址,在服务器中,0.0.0.0 指的是本机上的所有 IPv4 地址;在路由中,0.0.0.0表示的是默认路由,即当路由表中没有找到完全匹配的路由的时候所对应的路由。
参考:
CIDR
将一个前缀分为多个子网叫 子网划分,而将多个小前缀的地址合并为一个大前缀的地址叫 路由聚合,这个大前缀有时称为 超网。
在分类寻址中,网络大小只能是 A、B、C 中的其中一类,也就是前缀长度只能是 /8、/16、/24,这样会造成空间浪费。
CIDR(Classless Inter Domain Routing,无类域间路由) 的思想很简单,就是前缀可以是任意长度(当然,前缀的前几位始终和上层网络一致)。如果子网前缀分别是 /17、/18、/19 ,那么路由聚合后的超网就取其公共部分($\leq 16$)。
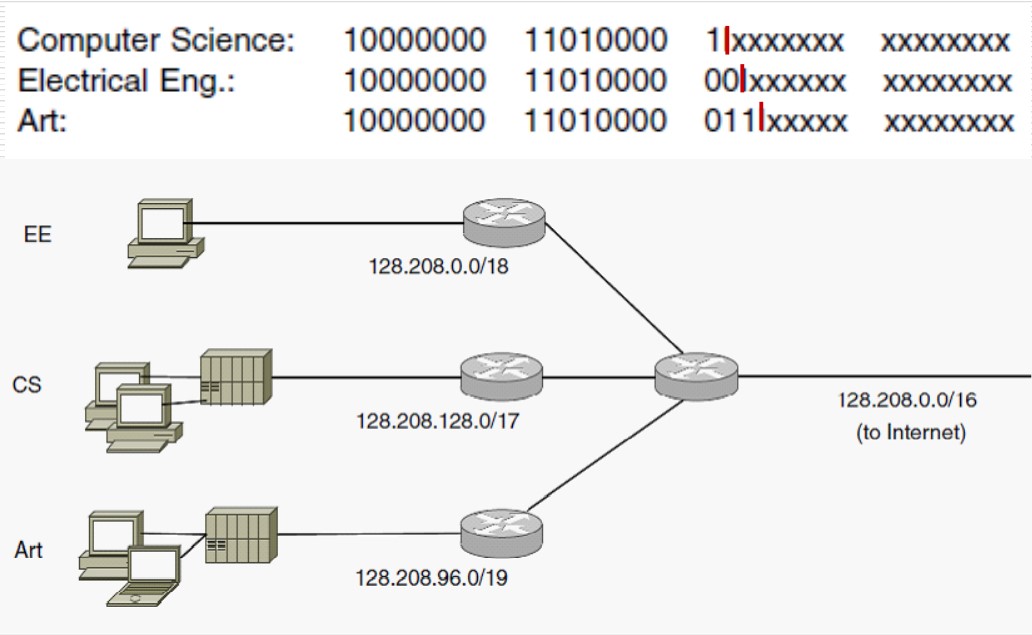
路由器使用子网掩码决定分组往哪个子网转发,路由器采用“AND ”操作(目的IP和子网掩码),得到目的网络地址,使用这种机制,路由器不必记录全部主机的IP地址,缩减了路由器的规模。
甚至,前缀允许重叠😳!举个例子,假如一个子网是 192.24.0.0,另一个平行的子网是 192.24.12.0,这时路由器会使用 最长匹配前缀,即尽量匹配最长的子网,假如一个数据包要发给 192.24.12.1,路由器在匹配到 192.24.0.0 后,发现更长的 192.24.12.0 也能匹配,就发给 192.24.12.0。显然,这种算法要求两个子网内的 IP 不能重叠。
由于 CIDR 的掩码可以是任意长度,不再局限于 /8、/16、/24,所以就需要 VLSM(Variable Length Subnet Mask,可变长子网掩码)。CIDR 和 VLSM 是配合使用的。
NAT
如果子网内的 IP 不够咋办?一种解决方法是动态分配 IP,只分配给活跃的客户端,但如果所有客户端都活跃咋办?这就需要 NAT(Natwork Address Translation,网络地址转换)
NAT 的思想很简单,几个人共用一个 IP 就好啦~ 对外都是同一个 IP 地址,对内则用另一套 IP 地址来区分不同客户端,然后通过 NAT盒 来进行转换。
对内使用的 IP 地址有三种:
- 10.0.0.0 ~ 10.255.255.255/8
- 172.16.0.0 ~ 172.16.255.255/12
- 192.168.0.0 ~ 192.168.255.255/16
宿舍/家里用的 WiFi 用的就是 NAT,一般家用 WiFi 可支持的终端数比较少,所以一般用的是第三种(你可以在手机的WiFi设置界面中看到 192.168 开头的 ip 地址)。
那两个 IP 地址如何转换呢?这时我们就要利用上层网络——传输层,传输层中用端口号来区分不同应用的传输。于是NAT盒就将内部ip+端口号映射到真实ip+端口号,从而实现网络地址转换。
这种映射每次都会变的,如果想要固定,必须手动设置端口映射。
IP 组网
了解完上面寻址方法后,就要利用这些方法给主机分配 IP,让它们组成一个网络。当然,可不能随便分,要规划好每个子网的大小,充分利用 IP 空间。顺便说一句,考试最后一道大题就考 子网规划 哟~ 😲
一般来说,上级会分配一个基础的 IP 地址,比如一个 B 类地址 202.38.197.0,然后我们从地址位的高位开始借位,用于划分子网:
11001010 100110 11000101 00000000 —— 202.38.197.0
01
10
11
↑
四个子网
某些教科书上认为 00 和 11 这样的全 0 和全 1 的子网是不允许的,但实际是可以的(那个不允许的协议早就废除了)。至于考试的时候嘛……我也不知道写什么。
IPv6
IPv6 用于替换 IPv4,可以解决 IPv4 的诸多不足。主要改进如下:
- 地址从32位升为128位
- 简化了分组头
- 更好地支持选项
- 安全方面的改进
- 服务质量的改进
IPv6 地址
IPv6 的地址的规定如下:
- 用十六进制表示;
- 每4个十六进制数之间用冒号隔开,共 8 组;
- 如果4个十六进制数前面是0,则可省略
- 全零组可以全部省略,用
::表示,但用一次(见下面的例子); - 地址前缀还是用 /xx 表示
IPv6 地址例子:
0001:0123:0000:0000:0000:ABCD:0000:0001/96
1:123:0:0:0:ABCD::1/96
1:123::ABCD:0:1/96
IPv6的特殊地址:
- 未指定:
::/128 - 环回地址:
::1/128 - 组播:
FF00::/8 - 链路本地地址:
FE80::/10(一般看到的IPv6都是这个开头) - 网点本地地址:
FEC0::/10
IPv6 过渡协议
- 双协议栈: 网络设备、网络系统必须有双协议栈的支持(两个一起用)
- 隧道技术:IPv6 作为分组封装在 IPv4 中,或反过来
- 翻译/转换技术:使用 NAT64 将 IPv6 地址转换为 IPv4 地址或反过来
路由选择协议(路由算法)
路由算法(routing algorithm)负责确定一个入境数据包应该被发送到哪一条输出线路上。路由和转发是两个不同的功能,简单来说,路由用于更新路由表,转发则负责使用路由表。
有两类路由算法:
- 非自适应算法(静态路由):路由是预先设置好的
- 自适应算法:根据拓扑结构和流量改变路由
汇聚树
最优化原理( Optimization principle ):如果一个路由器 J 处在路由器 I 到路由器 K 的最优路径上,那么,从路由器 J 到路由器 K 的最优路径也在同样的这条路径上。
汇聚树(sink tree):从所有的源到一个给定的目的的最优路径形成的一棵树,树根是目的。汇集树不必是唯一的。
静态路由选择算法
最短路径路由选择
“最短路径”有多种衡量方法,比如:
- 跳数
- 物理距离
- 延迟
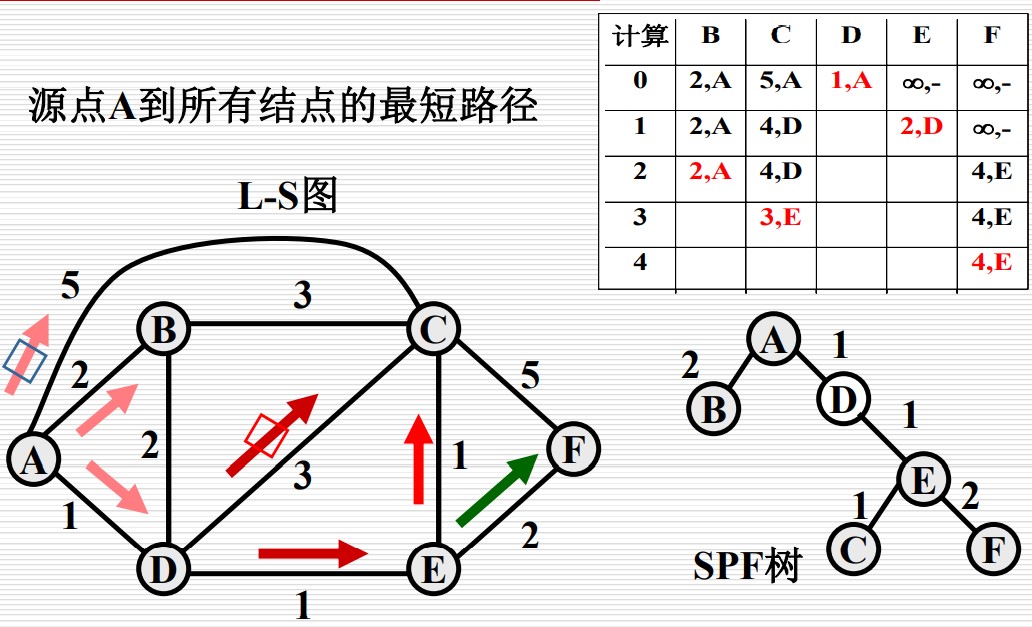
我们可以利用 Dijkstra 算法 来找到从源到目标节点的一条最短路径,步骤如下:
- 已知图的结构。假设 $i$ 是源节点,集合 $N$ 初始时为 $N={i}$,$D(v)$ 是 $v$ 到 $i$ 的最小距离;
- 找到一个不在集合 N 中的节点 w,$D(w)$ 最小,把 w 加入到集合中,对应路径也记录下来;
- 更新每个点的 $D(w)$,替换为 $\min{D(v),D(w)+(w,v)}$
- 重复2、3步骤,直到所有节点包含在集合 $N$ 中
- 最终得到一个 SPF 树
例子如下:
泛洪算法
泛洪算法:每个到达分组都被从除了到达端口外的所有其它端口转发出去(不计算路径,有路就走)。泛洪会产生大量重复数据包,解决的方法有:
- 在分组头增加一个计数器(counter),每经过一个节点,计算器减 1 ,当计数器变为零时,报文被丢弃。
- 每个节点设立一个登记表,当分组第二次到达时,被丢弃。
- 选择性扩散
泛洪的鲁棒性好,可靠性高,路径最短(因为能找到每一条可能的路径),常用于军事。
动态路由选择算法
为了实现动态路由,所有路由必须运行同一种路由选择协议,并且一台新的路由器必须主动介绍它自己,之后还要周期性地联系,以了解其它路由器的健康状况。
| 距离矢量路由 | 链路状态路由 |
|---|---|
| 从邻居看网络 | 整个网络的拓扑 |
| 在路由器间累加距离 | 计算最短路径 |
| 频繁、周期更新:慢收敛 | 事件触发更新:快收敛 |
| 在路由器间传递路由表的拷贝 | 在路由器间传递链路状态更新 |
距离矢量路由
距离矢量算法(DV,distance vector routing),简单来说就是:
- 每个路由器维护一张表,表中列出了当前已知的到每个目标的最佳距离,以及为了到达那个目标,应该从哪个目标转发的线路(端口)
- 邻居路由器之间交换路由信息(矢量)
- 每个路由器(节点)根据收到的矢量信息,更新自己的路由表
详解如下。假设第 i 个路由器的矢量为:
\[D_i= \begin{bmatrix} d_{i1}\\d_{i2}\\ \vdots \\d_{in} \end{bmatrix}\quad S_i= \begin{bmatrix} s_{i1}\\s_{i2}\\ \vdots \\s_{in} \end{bmatrix}\\ d_{i1}:从节点i到节点1的最短度量(代价)\\ s_{i1}:沿着从节点i到节点1的最短路径上的下一跳\]相邻路由器交换 $D_i$ 矢量之后,用如下公式更新矢量信息:
\[\begin{aligned} d_{ij} &= \min_{x\in A} [d_{ix}+d_{xj}]\\ S_{ij}&=x\\ \end{aligned}\\ \begin{aligned} &A:节点i的邻居集合\\ &d_{ij}:从节点 i 到节点 j 的最短距离\\ &d_{ix}:从节点 i 到节点 x 的最短距离\\ &d_{xj}:从节点 x 到节点 j 的最短距离 \end{aligned}\]D-V算法的特点:
- 优点:简单
- 缺点:
- 交换的信息太大了
- 路由信息传播慢,可能导致路径信息不一致
- 收敛慢,度量计数到无穷
- 不适合大型的网络
关于“度量计数到无穷”,可以形象地描述为“好 事传千里,坏事不出门”。我们考虑下图中的例子:左图中新加入了 A,经过 4 次交换就能找到最短路径;而右图中 A 断开,则 B、C 的度量会增加到无穷
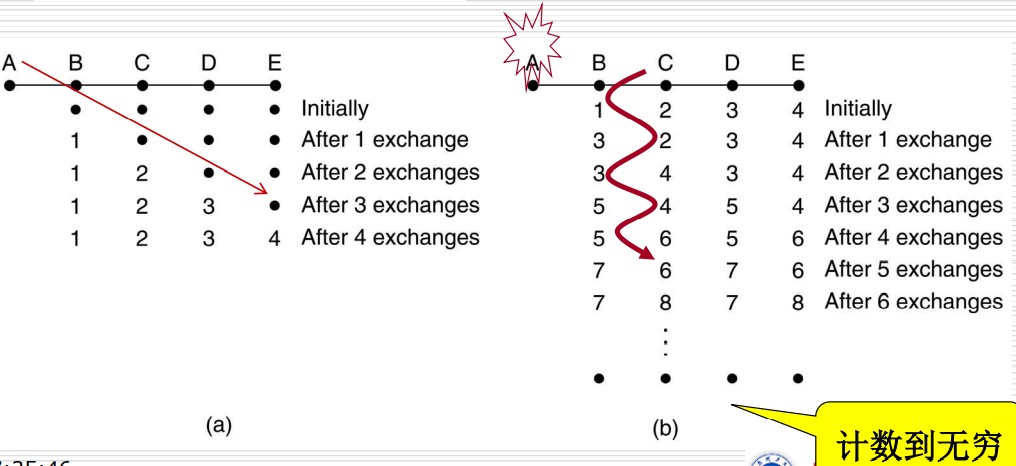
解决方法有:
- 定义路径度量(代价)的最大值
- 提高收敛速度
- 水平分割( Split Horizon):图中,C 禁止向 B 提供到达 A 的路由信息
- 毒性逆转(Poison Reverse):B 发现 A 不可达时,主动将到达信宿的距离改为$\infty$,并告知其他路由器
- 抑制定时器( Hold-Down Timers):当 B 发现 A 发生故障时,启动抑制计时器:
- a如果网络状态转变,down→up,关闭计时器,保留原有路由信息;
- 如果收到来自 C 的关于信宿的路由信息,且路径比原有路径短,则关闭计时器,更新路由信息
- 如果无上述两种情况发生,计时器到时,更新路由为信宿不可达。
- 触发更新(Triggered Updates ):当 B 发现网络 A 发生故障时,不等下一刷新周期到来,立刻更改路由为“信宿不可达”,引起全网的连锁反映,迅速刷新
D-V 算法中问题产生的根本原因是:路由器不知道路径信息,比如上面右图中,C 收到 B 的路径信息后,不知道自己是不是在这个路径上。要完全解决这个问题,就必须知道路径信息,也就是下面要介绍的 L-S 算法。
RIP
RIP 是一种使用距离矢量路由的路由选择协议。具体不多说。
链路状态路由
链路状态路由算法(LS,link status routing),简单来说就是:
- 发现它的邻居节点们,了解它们的网络地址
- 当一个路由器启动的时候,在每个点到点的线路(也就是向邻居)发送一个特别的 HELLO 分组
- 收到 HELLO 分组的路由器应该回送一个应答,应答中有它自己的名字
- 设置到它的每个邻居的成本度量
- 为了决定线路的开销,路由器发送一个特别的 ECHO 分组,另一端立刻回送一个应答
- 通过测量往返时间(round-trip time) ,发送路由器可以获得一个合理的延迟估计值
- 构造一个链路状态分组(LSA/LSP),包含它所了解到的所有信息,包括:发送方的标识、序列号、年龄、邻居列表、到邻居的成本/量度。
- 发送这个分组给所有其他的路由器,周期性地构造和发送,或者有特别的事件发生时构造,比如某条线路或邻居down掉了。
- 计算到每个路由器的最短路径:可以用前面的 Dijkstra 算法构造汇聚树。
下图是网络中每个路由器的 LSP。
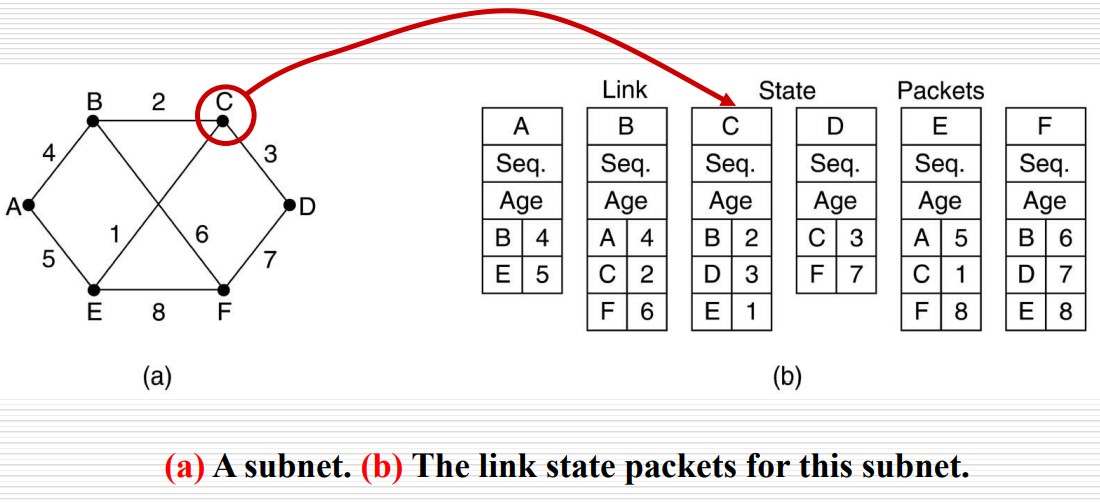
LSP 中的序列号会递增,当 LSP 传到下一个路由器时,该路由器记录下该序列号,如果该序列号是新的,就将这个 LSP 泛洪广播;反之就丢弃。
但序列号是有限位的,可能会导致新老序列号混淆。解决方法就是使用一个很大的序列号(32位)
如果路由器崩溃,或者序列号在传输过程中出错(某一位变成了 1导致序列号变大),也会导致新新老序列号混淆。解决方法就是使用 AGE 字段,每过 1s,AGE 减一,当 AGE=0 时丢弃对应的 LSP.
为了避免线路出错,路由器收到一个 LSP 后都需要回送一个确认。
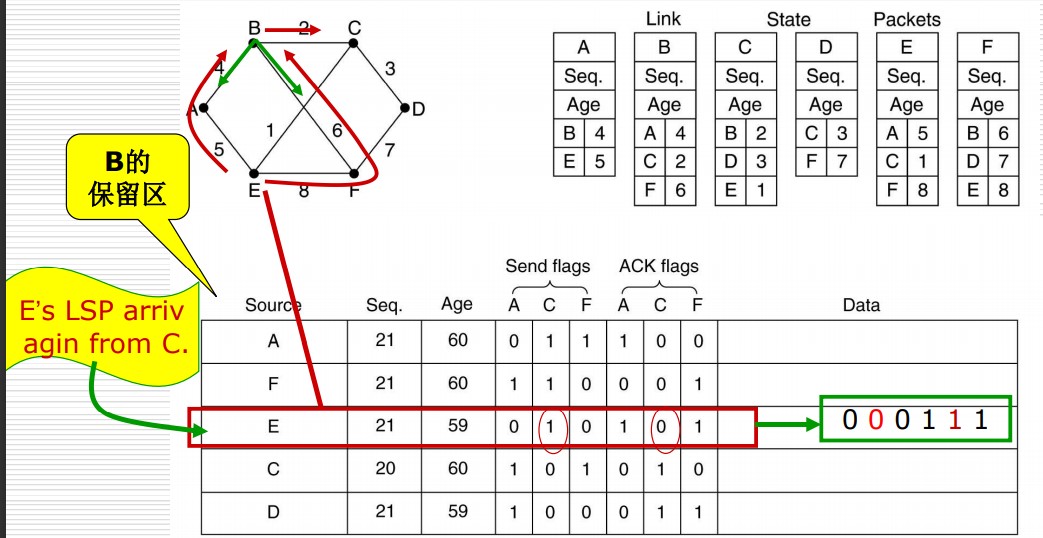
每个路由器维护一张 LSP 表,表中记录着它要向哪转发 LSP(send flags=1),以及要向哪回复确认(ACK flags=1)。下图中,当 B 从 C 收到 E 的 LSP 时,B 不必向 C 会送 E 的 LSP,所以 send flag 变为 1;同时 B 需要向 C 确认,所以 ACK flag 变为 1.
L-S 路由算法的特点
- 优点
*每个路由器的认识一致
- 收敛快
- 适合在大型网络里使用
- 缺点
- 每个路由器需要较大的存储空间
- 计算负担很大
OSPF
OSPF 是 L-S路由协议的实例,是目前。使用10^8/带宽作为度量值
OSPF 中有五种分组(packet):
| OSPF数据包类型 | 描述 |
|---|---|
| Type 1-Hello | 与邻居建立和维护毗邻关系。 |
| Type 2-数据库描述包(DD) | 描述一个OSPF路由器的链路状态数据库内容。(相当于网络的一个摘要) |
| Type 3-链路状态请求(LSR) | 请求相邻路由器发送其链路状态数据库中的具体条目 |
| Type 4-链路状态更新(LSU) | 向邻居路由器发送链路状态通告,收到 LSR 后或发送特别事件时发送 LSU |
| Type 5-链路状态确认(LSA) | 确认收到了邻居路由器的LSU |
OSPF 的运行步骤如下:
- 建立路由器毗邻关系
- Init:两台相邻路由器互发 Hello
- Exstart & Exchange:相邻路由器交换 DD 信息,根据 DD 信息,找到自己缺少的路由信息,并发送 LSR
- Loading:根据收到的 LSU,更新 LSP,并回复 LSA 确认
- Full adjacency(全毗邻):两台建立了全毗邻关系的路由器,LSP数据库完全一致。
- 选举DR和BDR
- 为了减少同步 LSP 数据库的次数,选取一个 DR,其余路由器只与 DR 同步
- DR是路由器选出来的,而非人工指定的;一旦当选,除非路由器故障,否则不会更换;DR 故障后,由 BDR 接替 DR 成为新的 DR
- 选取最老的路由器(priority),次选 Router ID 最大的。
- 发现路由
- 选择最佳路由
- 维护路由信息
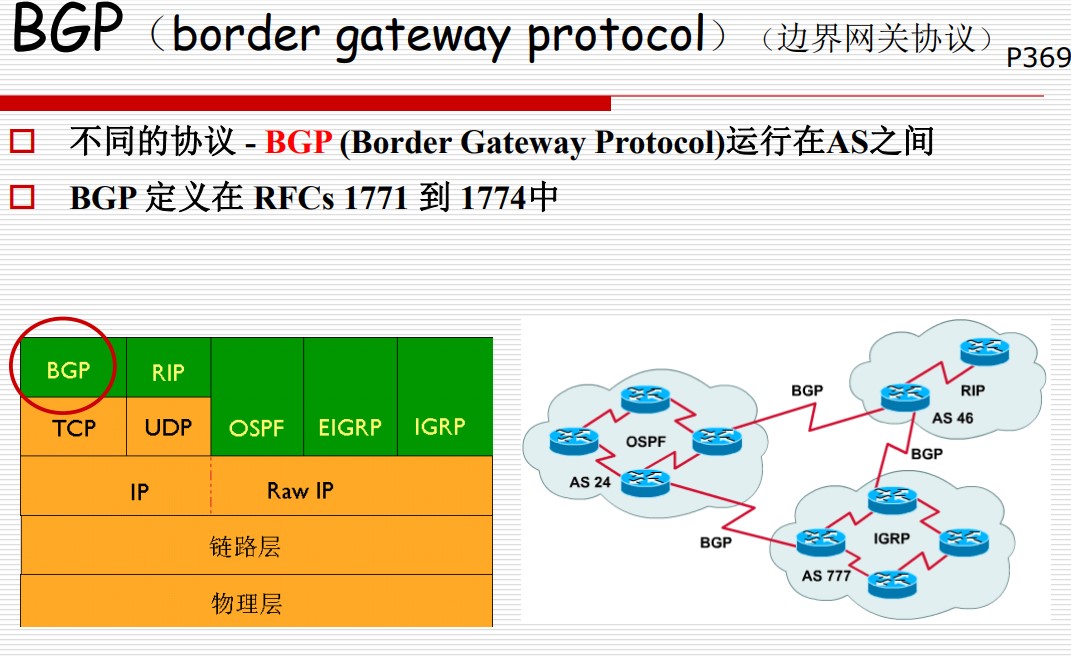
BGP
拥塞控制
总的来说,要控制拥塞,有两类方法:
- 开环(Open loop)
- 试图用良好的设计来解决问题,本质是从一开始就保证问题不会发生
- 开环决策制定不考虑网络的当前状态
- 闭环(Closed loop)
- 监视系统,检测何时何地发生了拥塞
- 把这些信息传递到能够采取行动的地方
- 调整系统的运行,以改正问题
下面主要讲闭环。
评价拥塞的量度有:
- 因为缺乏缓存空间而丢弃的分组百分比
- 平均队列长度
- 超时和重传的分组数
- 平均分组延迟
- 分组延迟的标准方差(standard deviation)
上述这些度量,数值越大表示拥塞的程度 越重。
检测到拥塞后,需要将拥塞信息告诉流量源,方法有两个:
- 每个分组可以保留一位或一个域,当拥塞度量超过阈值的时候,路由器填充该位或域,以此警告它的邻居。
- 主机或路由器周期性地向外发送探询分组,显式地询问有关拥塞的情况,然后,在有问题的区域利用回收的信息来路由流量 (类比:交通电台)
拥塞根源:负载 > 资源,所以解决拥塞的方法有两类:
- 增加资源
- 在某些点之间使用更多的通道增加带宽
- 把流量分散到多条路径
- 启用空闲或备份的路由器
- 降低负载
- 拒绝为某些用户提供服务
- 给某些用户的服务降低等级
- 让用户更有预见性地安排他们的需求
下面详细说说具体方法。一共有 5 种方法,根据起作用的快慢列在下图中:

- 网络供给
- 就是人为增加带宽,用备用路由或购买带宽
- 流量感知路由
- 通过改变路径的权重,改变路由路径
- 可能导致路由摇摆
- 准入控制
- 拒绝建立新的虚电路
- 流量调节
- 拥堵路由器通告源机发送慢下来,有下面三种方法
- 抑制包:路由器发送抑制包给源主机
- 显示拥塞控制:路由器在转发包时打上标记,当接收方发送应答包时,顺便通知源主机
- 逐跳后压:要上一跳减慢发送,可以很快缓解,但上游路径需要更多缓冲区。
- 负载脱落
- 最极端,直接丢掉一些分组
- 丢掉的分组:随机丢弃/丢新(文件传输类)/丢旧(多媒体类)/丢不重要(需要发送方标明)
流量整形
网络的服务质量(QoS,Quality of Service)有四个参数:带宽、延迟、抖动、丢失,不同网络应用的要求如下:
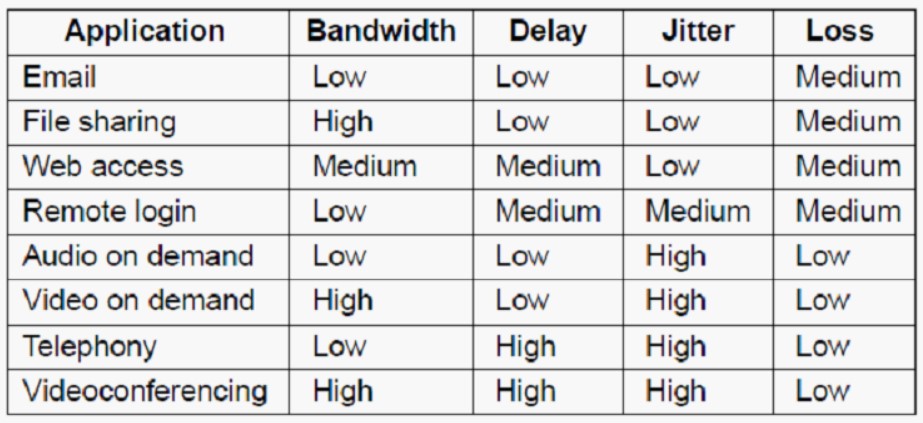
分组到达时间的变化量 (标准方差 standard deviation)叫做抖动 (jitter),在实时传输中,抖动可以引发问题,因为实时传输往往需要分组以恒定的速率到达
流量整形就是调节数据传输的平均速率(和突发数据流),减小抖动和拥塞。下面介绍两种算法:
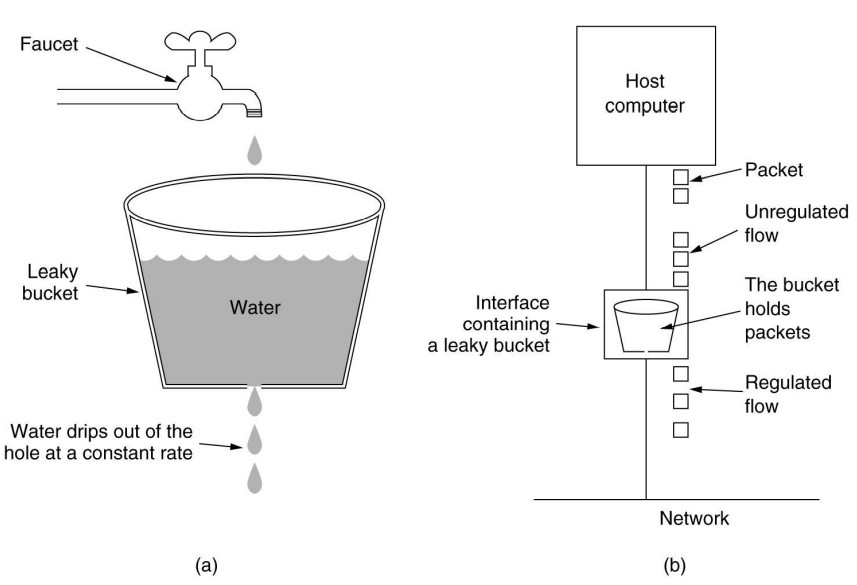
漏桶(leaky bucket):
- 每个主机连接到网络的接口中都有一个漏桶,即一个优先长度的内部队列
- 当桶中有分组的时候,输出速率是恒定的,当桶空的时候,输出速率是0
- 当一个分组到达满的桶的时候,分组将被丢弃(满则溢)
- 每个时钟嘀嗒( tick ),仅允许一个分组或固定数量的分组发送出去
一个简单的例子如下:
- 漏桶容量最多为 速率×持续时间,最少为 (产生速率-路由速率)×持续时间
- 最大突发事件 = 容量/(产生速率-路由速率)

漏桶的缺点:
- 当漏桶满了之后,数据将被丢弃
- 不能大量地突发数据
令牌桶算法:
- 令牌桶拥有令牌(tokens),且以每△T秒产生一个令牌的速度往桶中输入令牌
- 一个分组要发送的时候,它必要从桶中取出和获取到一个令牌
- 令牌桶算法允许累积令牌,但最多可以累积n(令牌桶的容量)个令牌
和漏桶算法相比:
- 令牌桶允许突发,但是最大突发受制于令牌桶容量的限制
- 当桶满的时候,令牌桶算法丢掉的是令牌(不是分组)
计算最大突发时间:设突发时间: $S$ 秒,令牌桶容量 $B$ 字节,令牌速率 $R$ 字节,最大输出速率 $M$ 字节,则:
\[B+RS=MS\\ S=B/(M-R)\]其他
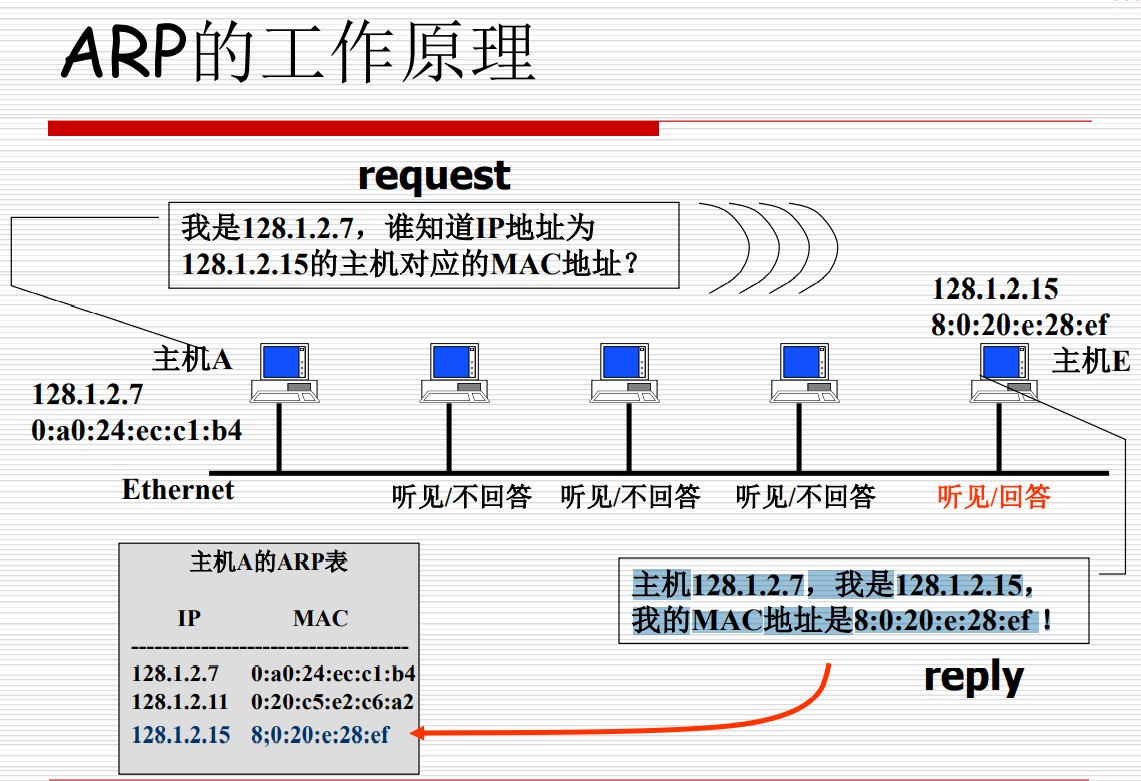
ARP
ARP(Address Resolution Protocol)的任务是找到一个给定IP地址所对应的MAC地址,可以用下面三张图来概括:
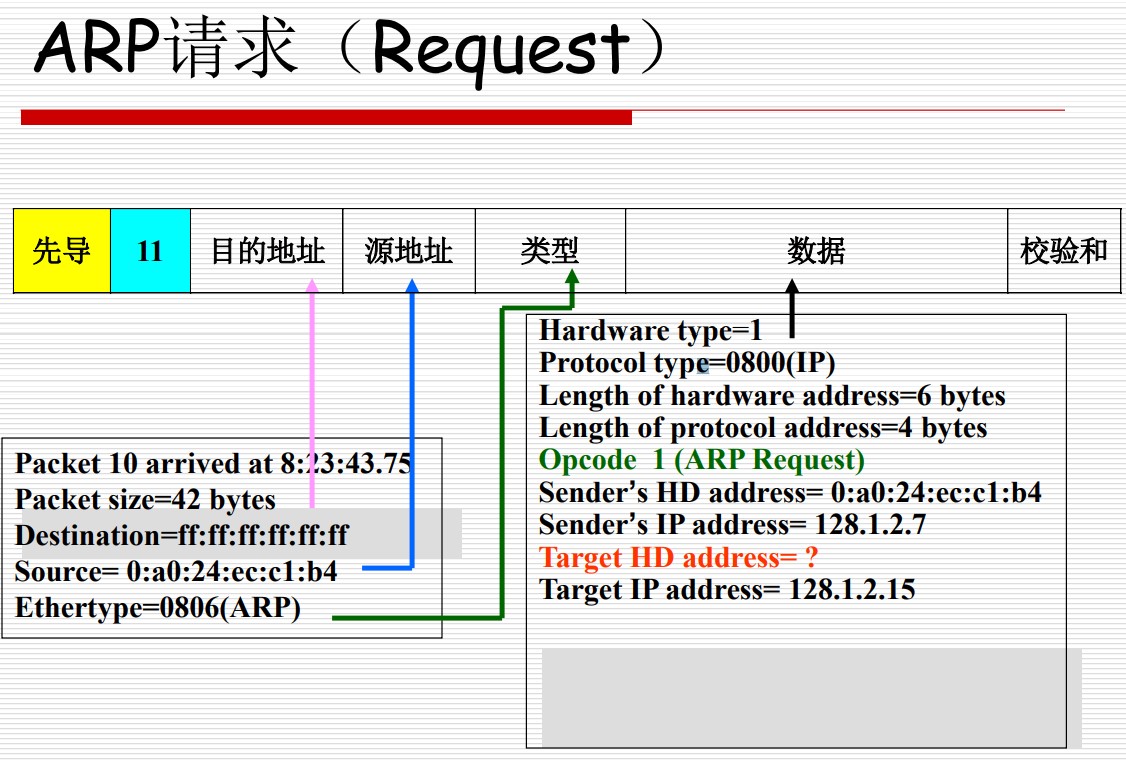
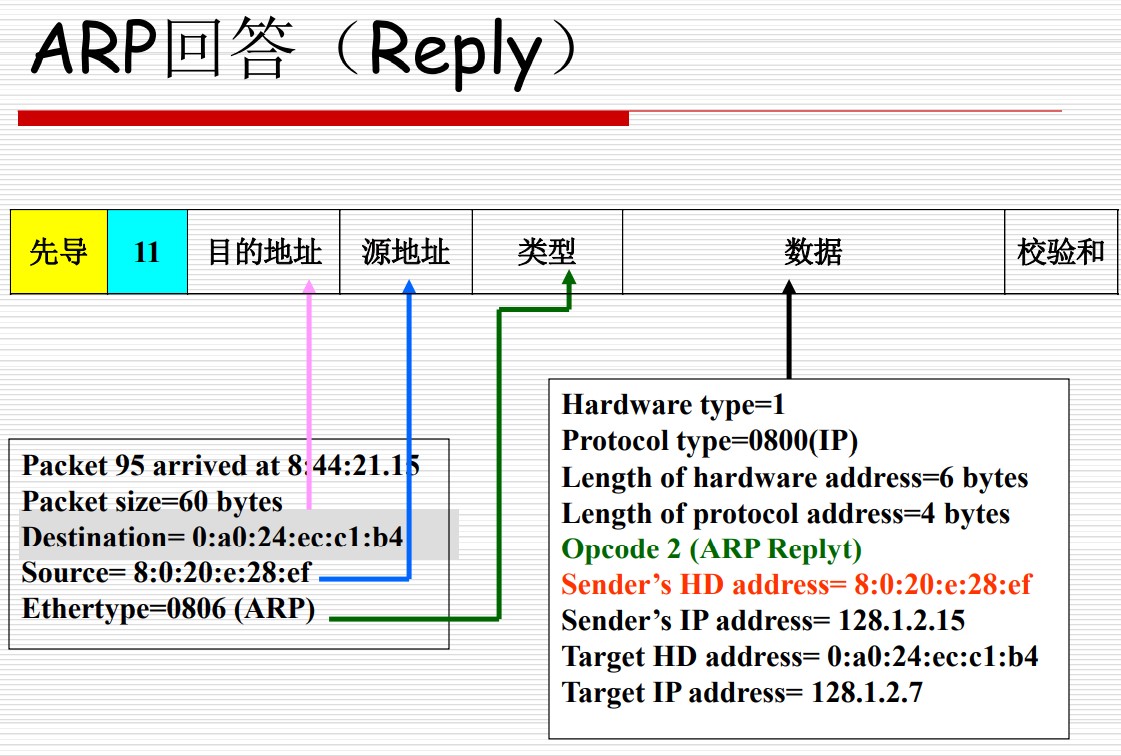
获取 IP 地址的方式
RARP
ARP 反过来就是 RARP,它广播自己的 MAC 地址,并请求知道自己的 IP 地址。
BOOTP
DHCP
- 使一台主机迅速并动态地获取一个IP地址
- 通过DHCP获取的 IP是租来的,可能会过期
- DHCP过程
- 初始化状态
- 选择状态
- 请求状态
- 绑定状态
推荐阅读
如果还是不理解路由器到底是怎么找到一个 IP 的,可以去看 dog250 写的 命题作文:在一棵IPv4地址树中彻底理解IP路由表的各种查找过程
如果不理解 OSPF 协议,可以去看 最通俗易懂的OSPF五种报文+七种状态